Det norske tollvesenet har en viktig oppgave i å håndheve tollregler og forhindre ulovlig import og eksport av varer.
De skal også sikre effektive prosesser, som involverer tilsyn med tollbestemmelser, verifisering av varedeklarasjoner, beregning av tollavgifter, og bistand til andre statlige etater langs Norges grenser.

I 2021 mottok tollvesenet nesten 10 millioner tolldeklarasjoner. Dette skaper enorme mengder data som blir analysert for å oppdage aktiviteter som strider mot regelverket.
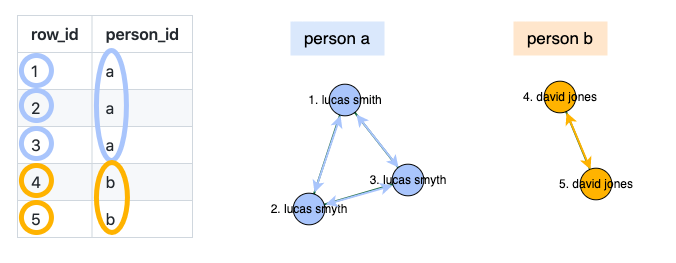
Tolldeklarasjoner sendes inn digitalt av ansatte i selskaper som sender varer til Norge. Denne manuelle deklarasjonen kan ofte inneholde skrivefeil eller variasjoner i hvordan navn eller adresser er skrevet. Dette kan føre til at én avsender kan oppfattes som flere forskjellige enheter.
Når data er unøyaktig, kan det som ser ut som flere ulike adressater, i realiteten være ett og samme firma. En aktør kan gjøre små endringer på skrivemåten til navn og adresser han sender ifra, noe som kan skjule mønsteret i forsendelsene og unngå å bli flagget ved kontroll.
Denne utfordringen gjør det vanskelig å få en omfattende oversikt over varer som blir importert til og eksportert fra Norge. Manuell validering av millioner av oppføringer er ikke et alternativ, og det er her kunstig intelligens kommer inn i bildet.

For en tid tilbake engasjerte Toll Nasjonalt kompetansesenter for HPC for å få bistand til å demonstrere hvordan Entity resolution, eller objektidentifisering kan brukes til å rydde opp i datakvaliteten.
Objektidentifisering er en gren innen kunstig intelligens som har som mål å identifisere dataoppføringer som tilhører det samme objektet i den virkelige verden, som for eksempel selskapsnavn eller adresse. Dette er nyttig når man slår sammen data fra forskjellige kilder, i deteksjon av svindel og i kundebehandlingsstyring.
Hvis to oppføringer er veldig like, kan vi si at de samsvarer, og at de sannsynligvis er like. Men i en database med millioner av oppføringer vil det ta alt for lang tid å sammenligne hver enkelt oppføring med alle andre oppføringer i registeret. Så i stedet velger vi bare ut de parene som mest sannsynlig samsvarer, basert på om de har noen detaljer til felles. Dette gjør prosessen mye raskere.
En programvare som heter Splink kan hjelpe oss med å vurdere hvor viktig hver detalj er for å bestemme om to oppføringer refererer til det samme. Splink justerer disse vurderingene til den finner den beste modellen for dataene, og kan håndtere 2 millioner oppføringer på en bærbar datamaskin. For større datamengder kan den bruke kraftigere systemer som Spark og AWS Athena, men til å trene større maskinlæringsmodeller trengs kraften fra superdatamaskiner.

Nå hjelper vi Toll med å etablere en maskinlæringsarbeidsflyt for å rydde i dataene og knytte sammen datapunktene som algoritmene ser som samme entitet eller adressat. Slik kan kunstig intelligens hjelpe til med å gjøre grensene våre sikrere.